Recommender System
Purpose of this project to develop a recommended system from scratch. Best approch to learn any concept, is to implement it.
Abstract:
Recommender System / Machine is developed to suggest end user with the product ( can be anything likes movies, sports, food etc.) based on user interest. There are many ways to predict about end user interest. One of the most popular ways to keep track of user past, interest and suggest him/her according to his/her history(commonly known as content based recommendation). The positive side of this approach , it is simple and easy to develop, but the downside of it, the user may get monotonous suggestion and every time he will get the same kind of suggested product. Other approach can be a collaborative recommendation, where user not only get recommendations based on his/her interest but, also based on other similar user who matches with his/her interest to certain thresholds. It helps user to explore new area which he did not explore, but he may find it interesting once introduce it to them.
Search
Todays we have lots of data available in every field of study. With so many data we have access to any information, but large chunk of data has its own challenges. Due to large amount of data search for specific information has become challenging. To speed up search and retrieve the accurate data many search algorithms has developed. One of them is calculating similarity between query and document using vector space model (VSM) where vsm is created using tf-idf.
Idf
Inverse Document Frequency introduce to reduce impact of term which occur too frequently in all document. Idea here to give more importance to the term which occurs many times in few numbers of document.
Idf is define as
idf = log ( N/dft)
Where N = number of document
dft = number of document terms appears.
TF
Terms frequency measure how frequently a term occurs in document. It is defined as number of times term appears in document divided by total number of terms.
Tf = (number of time term t appear in document)/ total number of terms.
Tf-idf define as terms frequency multiple by inverse document frequency.
Tf-idf = tf * idf
Vector space model
Vector space model is used to store algebraic information of textual document. One of the ways to store algebraic information is tf-idf which we are covering in this blog.
Cosine similarity
Cosine similarity is one of way to measure similarity between two document or between document and query.
Cos(d1,d2) = dot(d1,d2) / (||d1||*||d2||)
Query search algorithm
Calculate the term frequency
Calculate inverse document frequency
Create vector space model using tf-idf
Calculate similarity between document and query using cosine similarity
Retrieve document based on cosine similarity
Implementation details
Calculating idf
def Calculate_Inverse_Document_Frequency(self,term):
#calculate idf for given term
#idf = log(Number of document / Number of document term appeared)
if term in self.dict:
return math.log(self.totalDocument/self.docF[term],2)
else:
return 0
Create Document Vector
create tf-idf weight vector of query term for document
def Make_Document_vector(self,query_token,id):
unique_Q_terms = set(query_token)
document_vector = []
for q_term in unique_Q_terms:
if q_term in self.dict:
if id in self.postings[q_term]:
tf = self.postings[q_term][id] / self.length[id]
tf_idf = tf * self.Calculate_Inverse_Document_Frequency(q_term)
document_vector.append(tf_idf)
else:
document_vector.append(0)
else:
document_vector.append(0)
return document_vector
Create Query Vector
create tf-idf weight vector of query term
def Make_Query_vector(self,query_token):
unique_Q_terms = set(query_token)
query_length = len(query_token)
vector = []
for term in unique_Q_terms:
term_count = query_token.count(term)
term_F = term_count / query_length
query_idf = self.Calculate_Inverse_Document_Frequency(term)
tf_idf = term_F * query_idf
vector.append(tf_idf)
return vector
Calculate cosine similarity
calculate cosign similarity of two tf-idf vector
def Calculate_similarity(self,query_vec,doc_vec):
return dot(query_vec,doc_vec)/(norm(query_vec)*norm(doc_vec))
Searching the query
We perform cosine similarity between query and document space vector.
Classification
Classification problem can be defined as “deciding class for unknown data based on its feature and learning from old known data and its classes”. As an example, lets we have a dataset of spam and regular email. After looking into these data set, we decide some feature specific these data like sender, subject line, external link and domain. These features can act as a dimensionality of dataset.
We have different Machine learning algorithm which help with training and classification problem. Logistic Regression, naïve based classifier, Support Vector Machine (SVM), Decision Tree, Neural Network and many more. Each algorithm has their own specification and they work better for specific data set. We don’t have any general algorithm which work better for all data set.
Project specific.
Naïve Based classification
Naïve Based classification assume each feature (in many literatures also refer as dimension are independent of each other). It is simple probability-based classifier. It uses Bayes probability theorem to solve classification problem.
Mathematical representation of Bayes Theorem
P(A|B) = P(B|A) * P(A) / P(B)
If we consider movie data set the formula will become
P(y|X) = P(X|y) * P(Y) / P(X)
According to naïve bayes each feature is independent of each other
P(y|x1,x2,…..xn ) = P(x1|y)P(x2|y)..P(xn|y) P(y) /(P(x1)P(x2)…..P(xn)
Visit https://nlp.stanford.edu/IR-book/pdf/13bayes.pdf for detailed clarification.
Implementation Details.
Class CNaiveBayes.py
Responsible to perform Naïve classification and return probability-based class
Variable description
ClassF : store classfrequency/ Probablity
queryClassPrabablity : store Probablity of class given term
ClassTermCount : to store each class has how may total term
TermClassFrequency : to store count of term in each class
Method Description
Tokenize : create token from the string description and remove stop word(common word)
def tokenize(self, description):
if pd.isnull(description):
return []
else:
terms = description.lower().split()
# remove stop word
filtered = [word for word in terms if not word in stopwords.words('english')]
return filtered
Initialize : Perform Basic Initialization Operation Reading data, create token and initialize each class variable.
for term in u_term:
#updating count of each term
self.ClassTermCount[current_class].add(term)
self.TermClassFrequency[term][current_class] = self.TermClassFrequency[term].get(current_class,0) + u_count[term_index]
term_index += 1
CalculateClassProbability : Calculate probability of each class based on data.
for key in self.ClassF:
self.ClassF[key] = self.ClassF[key] / self.totalDocument
CalculateTermProbablity : Predict probability of term based on naïve bayes
for key in self.ClassF:
#print((self.ClassTermCount[key]))
currentProb = self.ClassF[key]
#with each term loop will expand to P(x1|y)P(x2|y)..P(xn|y) P(y)
for term in terms:
currentProb = currentProb * (( self.TermClassFrequency[term].get(key,0)+1) /( len(self.ClassTermCount[key]) + len( self.unique_terms)))
self.queryClassPrabablity[key] = currentProb
print(currentProb)
if currentProb > probablity:
probablity = currentProb
className = key
Accuracy measure from implementation
Training Accuracy = 97.5%
Test Accuracy = 35.0 %
Recommendation
Recommendation is being used to suggest its user a product which he is most likely to be interested. Recommendation engine is developed based on user profile and product he liked in past.
Recommendation engine method.
Content based recommendation
User Collaborative recommendation
Content based recommendation
In content-based recommendation user get recommendation based on his selection about product in past.
User Collaborative recommendation
In this approach first we calculate similarity between two users based on common item they liked. After calculation similarity we recommend product which is like by most similar user to another user.
Pitem = Ʃ ( Rvi * Suv) / Ʃ (Suv)
Pitem = Predection of item
Rvi = user v rating to item i
Suv = similarity between user uv
Implementation details
Create Model : To create matrix of user and item rating
def CreateModel(self):
self.totaluser = self.ratings.user_id.unique().shape[0]
self.totalmovie = self.ratings.movie_id.unique().shape[0]
self.item_matrix = np.zeros((self.totaluser+1, self.totalmovie))
#random generated data for end user
self.item_matrix[1, :] = np.random.randint(6, size=self.totalmovie)
#print(self.item_matrix[1, :])
for line in self.ratings.itertuples():
#print(line)
self.item_matrix[line[1] , line[2]-1 ] = line[3]
Calculate similarity between user
def CalculateSimilarity(self):
self.usersimilarity = pairwise_distances(self.item_matrix, metric='cosine')
self.itemsimilarity = pairwise_distances(self.item_matrix.transpose(), metric='cosine')
Prediction of item
def Predict(self, type='user'):
if type == 'user':
mean_user_rating = self.item_matrix.mean(axis=1)
# We use np.newaxis so that mean_user_rating has same format as ratings
ratings_diff = (self.item_matrix - mean_user_rating[:, np.newaxis])
self.prdiction = mean_user_rating[:, np.newaxis] + self.usersimilarity.dot(ratings_diff) / np.array(
[np.abs(self.usersimilarity).sum(axis=1)]).transpose()
elif type == 'item':
self.prdiction = self.item_matrix.dot(self.itemsimilarity) / np.array([np.abs(self.itemsimilarity).sum(axis=1)])
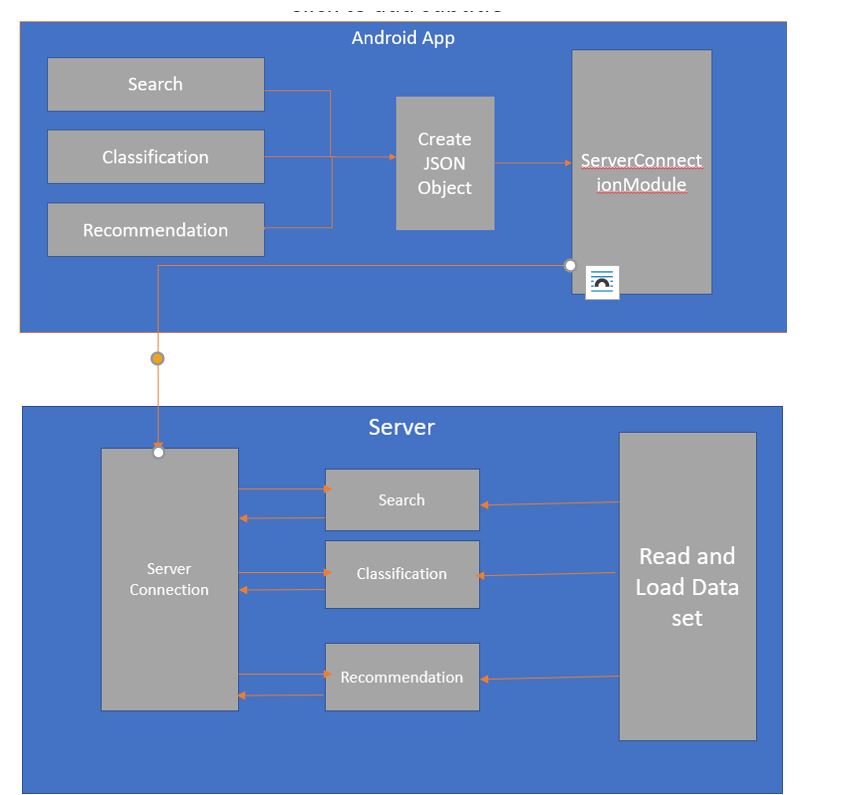
Android Application
I have developed android application to communicate to server and show result of search, classification and recommendation to user.
I connect to server using java HTTPAsyncTask class. I send data using POST method in json object and receive result from server in the form of json object.
For Code and Implementation detail visit Git hub
Dataset
Dataset primary refer as a collection of similar type of index data which can be used for special purposes. With time and technology data set are becoming huge and tradition approach (normal SQL queries) is not sufficient to store and retrieve data from data set. To tackle this situation big data come into picture. It helps with fast data retrieval with proper indexing. The first step towards developing any recommender system is to finalize data set. According to data set we can plan our approach and decide which feature is important to create our recommender system. Click here to visit movielens.
To explore more dataset click here.
More movie dataset.
Reference
https://github.com/mnielsen/VSM/blob/master/vsm.py
http://blog.josephwilk.net/projects/building-a-vector-space-search-engine-in-python.html
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/
https://nlp.stanford.edu/IR-book/pdf/13bayes.pdf
